This whitepaper outlines what we believe are the most important questions enterprise leaders must ask before rolling out AI agents that are deeply integrated in their software infrastructure. We introduce the concept of an agent's "blast radius" and explain why it matters. We then present four dimensions along which unmanaged agent access creates compounding risk, and discuss the tradeoffs of different approaches to managing each one: enforcing data access patterns, maintaining full traceability of agent activity, building integrations once and decoupling them from individual applications, and staying agnostic to interfaces, frameworks, and providers. This paper condenses our learnings from the past year helping large enterprises manage AI integrations and agent rollouts at superglue. We wrote it both as a practical resource for enterprise leaders navigating these decisions and to articulate the problem space we are building for.
AI Agent Blast Radius
Rolling out AI agents with deep integrations is not only a technical challenge. As AI-assisted tooling erodes the cost of implementation, organizational challenges begin to play a more important role. Chief among them is what we call an agent's "blast radius": the totality of systems, tools, credentials, data, and human users an agentic AI application can interact with. Each added MCP server, externally installable skill, integration, and end user expands this surface area. With a larger blast radius, the probability of both human and agent failures resulting in data leaks, tool misuse and data access chaos increases. Enterprises need to design structures and guardrails that contain this blast radius, ideally before rolling out agentic AI applications, not after.
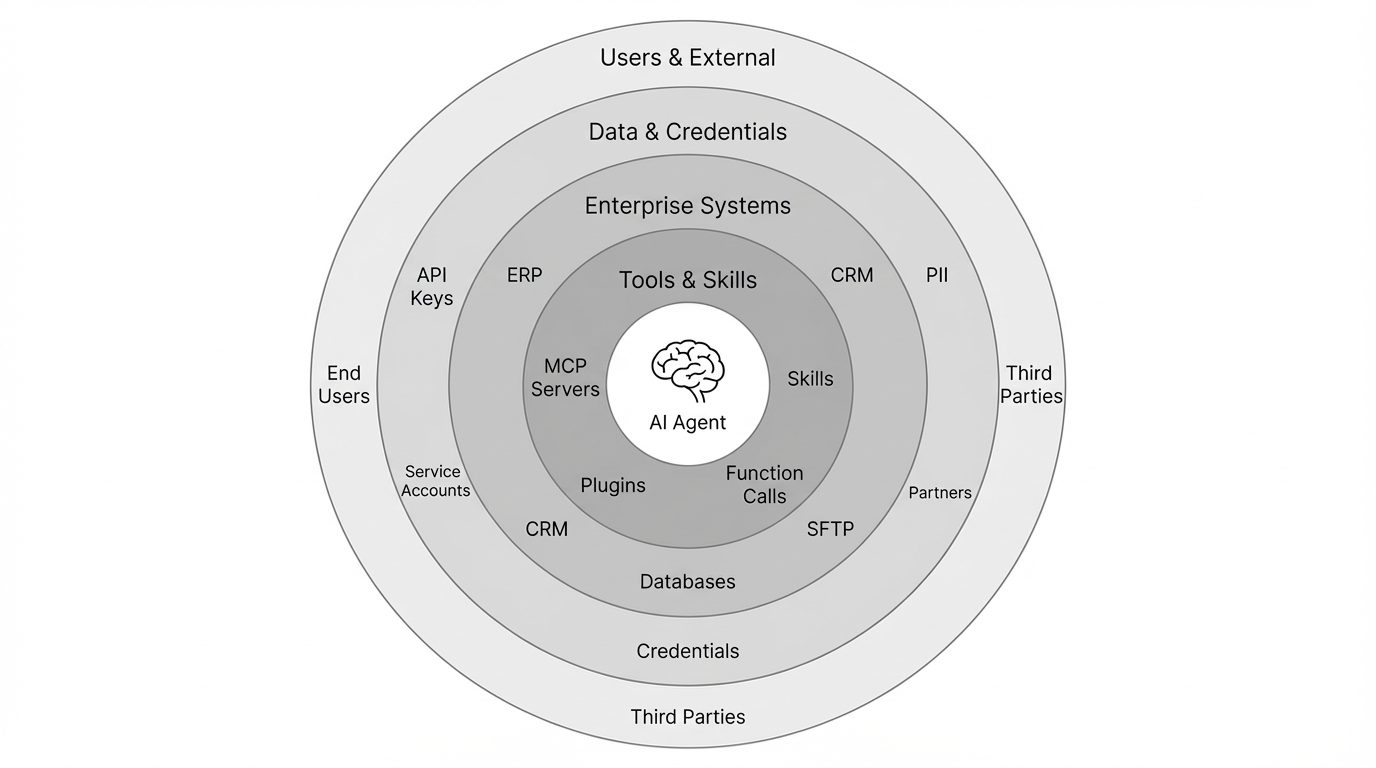
The following four questions map directly to the dimensions of this blast radius. Each one addresses a specific axis along which unmanaged agent access creates compounding risk: where access is enforced, whether actions are reconstructable, whether integrations compound or sprawl, and whether tools survive interface shifts.
1. Where are agent data access patterns enforced?
The growing number of AI applications used in enterprise organizations requires formulating a consistent and scalable strategy for enforcing AI data access patterns. At superglue, we have seen three enforcement models: at the AI application layer, at the system-of-record layer, and via an application-agnostic intermediate integration layer. Each enforcement model carries different tradeoffs in convenience, scalability and risk containment.
Agentic AI application layer
In this model, AI data access logic lives in the AI application logic itself. Defining access patterns at the application layer is beneficial for simplicity and ensuring self-contained rollouts, but usually breaks as the number of applications and systems these applications access grows over time. This also leads to duplicated access logic across applications, inconsistent enforcement policies, and lack of transparency. When data access patterns are defined in prompts or model instructions, they are neither deterministic nor auditable.
System-of-record layer
In this model, AI agents are treated as users within existing enterprise IAM systems. This may involve assigning service accounts to agents or managing access through permissioning roles. This often seems attractive since it leverages established IAM infrastructure, is familiar to enterprise security and data governance teams and works well for single system integrations. These systems were primarily designed for human users. While AI agents may act on behalf of humans, they often require more fine-grained, tool-level scoping and are unlikely to map well to existing IAM roles. If agents are accessing several systems, this approach also requires maintaining a large number of system-level roles per agent, which represents a maintenance burden and does not scale well.
Intermediate integration layer
In this model, access control is enforced in a system- and application-agnostic layer that sits between AI applications and enterprise systems. This layer becomes the source of truth for fine-grained tool-level permissioning, agent-to-human user attribution, credentials management, and audit trails. Instead of embedding access enforcement logic inside application code, prompts, or IAM systems, access is enforced at the integration boundary. This ensures that access rules are defined once, applied consistently and can be enforced at tool-level, system-level, per end-user credential and any other level of required granularity. It also ensures that tools are not duplicated and that AI applications all consume the same integration infrastructure.
This approach introduces tradeoffs. An intermediate layer adds operational complexity: it must be deployed, monitored, and maintained as critical infrastructure, since it becomes a single chokepoint through which all agent tool-calling activity flows. It can also add latency to tool invocations and requires upfront investment in defining tool-level access policies before AI applications can go live. For organizations with only a small number of AI applications accessing well-scoped systems, this overhead may not always be justified. The benefits compound as the number of applications, systems, and end users grows. This is precisely when the other two models begin to break down and why this is the model most suitable to enterprise settings.
The enforcement model an enterprise chooses directly determines how effectively it can contain an agent's blast radius. When access logic is scattered across application code and prompt instructions, the blast radius is effectively unmanaged. An intermediate integration layer provides a boundary where every tool invocation, credential use, and data access event can be validated before it reaches the systems beneath it.
2. Can you reconstruct every action your agents take?
As agentic AI applications become increasingly autonomous, determining who exactly is accountable for what data an agent accesses becomes more complex. Enterprises often deal with sensitive, proprietary, and personally-identifiable data. Even if comprehensive data governance structures are in place, it is important to maintain full traceability and monitoring of agentic data access patterns to identify weaknesses in data governance structures. To do this at scale in an enterprise setting, it is not sufficient to simply log all activity of agentic AI applications. Instead, enterprises need to set up monitoring systems that are able to reconstruct:
- Which AI application and which human user initiated the action?
- Which systems, endpoints, files, and records were accessed?
- What exact data was retrieved, and where could this data have been written to?
Enterprises typically approach this in one of two ways. The first is application-level logging, where each AI application independently records its own activity. This is straightforward to implement but produces fragmented audit trails — reconstructing a cross-application data flow requires correlating logs across systems with no shared trace identity. The second is integration-layer observability, where tracing is enforced at the same boundary where tool invocations are executed. This produces a unified audit trail with consistent trace IDs, tool-level granularity, and full input/output capture. The downside is that it requires that all agent activity flows through this integration layer and that payloads and tool results are captured without introducing latency or high storage costs.
In both cases, the key tension is between completeness and overhead: capturing full granular request data allows deterministic reconstruction but generates significant data volume, while summary-level logging is cheaper but leaves gaps that make post-incident retracing incomplete.
Carefully considering observability tradeoffs is a fundamental requirement for any enterprise building integrations for rolling out agentic AI applications and something that is often only considered after the fact. A comprehensive monitoring framework should allow replaying of runs, inspection of intermediate tool results, and tracing of exact outputs that were exposed to an agent. When observability and monitoring structures are not established, assessing and controlling an agent's blast radius is very difficult.
3. Are your integrations reusable across AI applications?
Agents without tools only scratch the surface of what is currently possible. Enterprises need to decide which tools in their vast IT landscapes to give agents access to. This involves considerations around authentication mechanisms, APIs, and level of standardization and sensitivity of data. When using pre-built connector stores, this is a solved problem only as long as enterprise teams stick to using existing pre-built tools. This breaks down as soon as AI applications require custom authentication mechanisms or integrate with non-standard systems that connector libraries do not cover. For integrations to be truly reusable across AI applications, they must be:

Decoupled from the application logic — Integration logic should not live inside prompts, frontend applications or individual backend services. Integration tools should be usable as part of a standalone execution layer that any AI application can call.
Versioned — APIs, databases, and enterprise systems evolve over time. Integrations need to evolve alongside these systems and support version tracking, safe rollbacks, and historical run attribution.
Credential-isolated — In multi-tenant environments, integrations may need to support runtime credentials and be usable for different human tenants.
As the number of AI agents in an enterprise grows across departments and products, portable integration infrastructure becomes a force multiplier. Enterprises that are able to invest early into reusable, versioned, and observable integration layers avoid integration sprawl and ultimately accelerate AI application rollouts substantially.
4. Are your tools portable across interfaces?
As enterprises experiment with chat-based copilots, MCP-based agents, CLI tools, agent skills, and scheduled automations, integrations must be interface-agnostic. Interfaces and AI agent development standards are among the most dynamic parts of the modern AI stack. If integrations are tightly coupled to a specific SDK, a specific standard, or a specific tool-calling mechanism, every interface shift will force a rebuild of the integration layer. For integrations to be truly portable, they must meet three criteria:
Stateless execution — Integration tools should accept inputs and return outputs without relying on interface-specific session state or AI agent context windows. Integration tools need to produce the same results irrespective of the interface they are used in.
Standard I/O contracts — Tool definitions should be describable in a generic schema format (e.g. JSON) rather than bound to a format specific to a particular framework or agent provider. This allows any interface to discover and invoke an integration tool in a consistent manner.
No interface-specific dependencies — Tool definitions should not rely on SDK-specific libraries, agent framework internals, or obscure syntax. As soon as they do, interface migrations require modifying tool definitions themselves rather than just the invocation layer.
When tools are portable, teams across enterprises can easily adopt new AI interfaces without waiting for integrations to be rebuilt. When they are not, each integration becomes a bottleneck that slows down adoption of new applications. Enterprises that embrace this approach in their integration design avoid this and preserve flexibility as agent interfaces and standards continue to evolve.
Conclusion
The four questions outlined in this paper are not independent concerns. They are highly interconnected and should be core to any enterprise agentic AI rollout strategy. An enterprise that enforces data access patterns at the application layer will inevitably struggle with auditability. An organization that builds tightly coupled integrations will face portability challenges as interfaces evolve. Teams that treat reusability as an afterthought will find themselves rebuilding the same integration logic for every new AI application they roll out.
The common thread across all of these questions is the need for an intermediate integration and agent data governance layer. One that is decoupled from both the AI applications above it and the enterprise systems beneath it. This layer must serve as the single source of truth for tool definitions, credential management, permissioning and execution history. It must support fine-grained, per-user access control without relying on prompt-level enforcement. It must produce complete, replayable audit trails for every action an agent takes. And it must expose integrations through standardized interfaces that remain stable as the agentic AI ecosystem continues to shift.
Enterprises that defer these architectural decisions will pay for it in integration sprawl, governance gaps, and compounding technical debt. Those that invest early in a dedicated integration layer will be positioned to scale agentic AI adoption without scaling risk proportionally.
The challenge here is organizational commitment: treating AI integration infrastructure with the same rigor as data platforms, identity access systems, and API gateways. Enterprises that recognize this and begin integrating their AI applications with existing infrastructure through a principled, governed integration layer will roll out agents faster and with the confidence that every action is traceable, every integration is built to last, and every agent's blast radius is understood and contained.